
特征平台(Feature Store):Feast

承接上一章《特征平台(Feature Store)综述:序论》,本章对发布自2019年,并持续更新至今的特征平台Feast进行回顾。
本章内容基于Feast v0.12版本的文档和代码进行分析。
总体架构

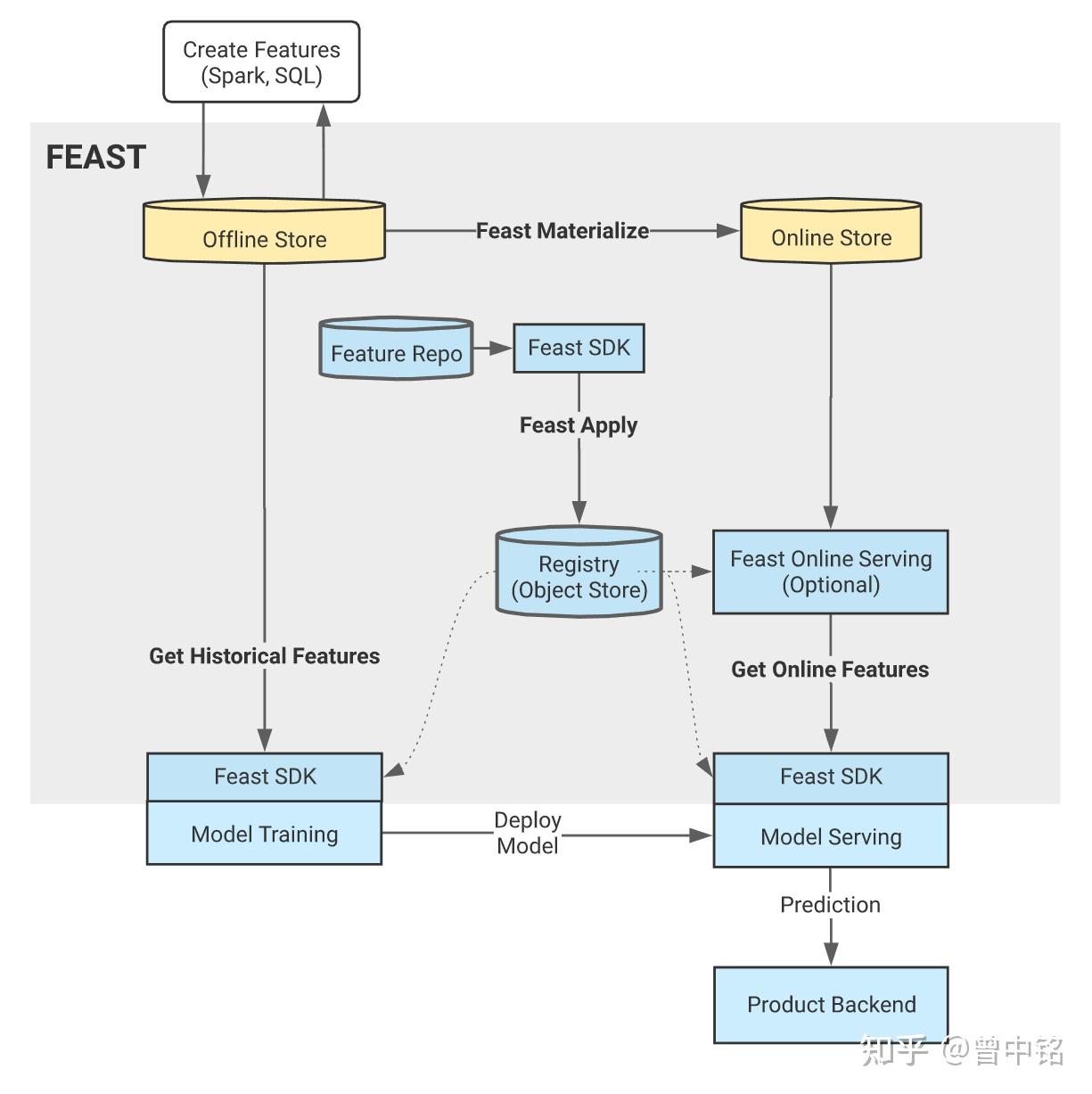
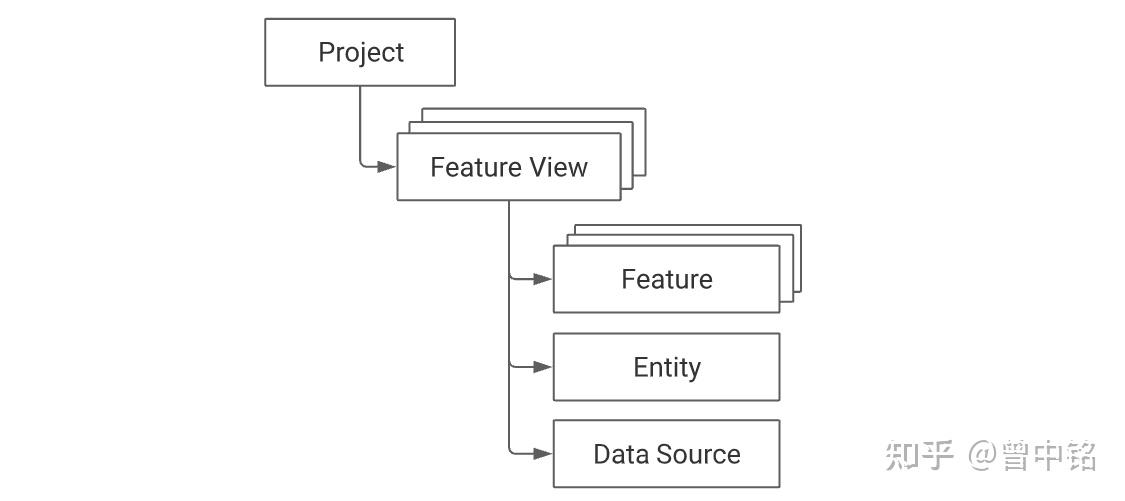
核心概念
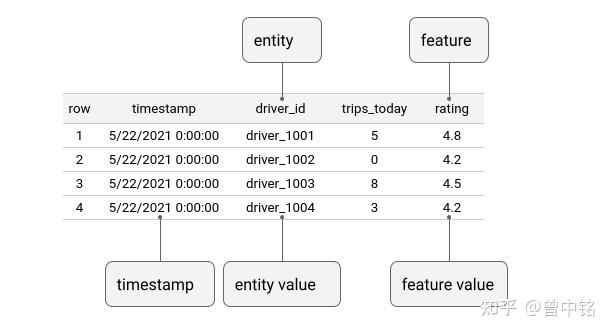
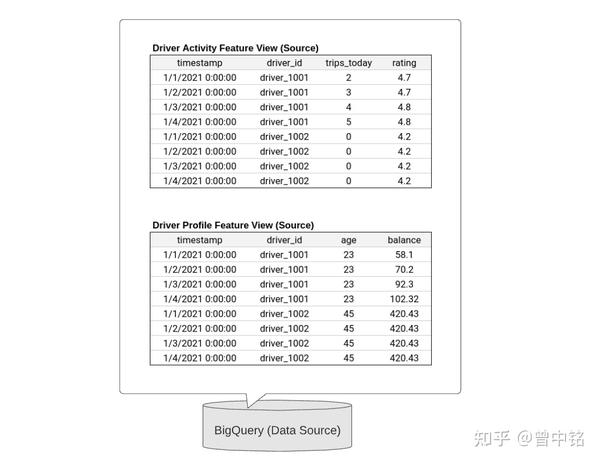
Data Source
Data Source实际是一张时序表,内部存储了在不同时刻,Entity(在此为司机ID)对应的Feature值(今天的订单量、评分值)。

Entity
作为Feature View的数据主体,是特征存储、消费、复用的关键。
Entity可能由Data Source表中的单个或多个字段来确定(即数据库表中的单主键/联合主键)。
Feature View
Feature View是封装某一特定实体(Entity)的一组特征(Feature)的对象。
作为Feature Store的核心概念,以下能力均围绕Feature View建设起来:
- 训练数据生成:一个训练数据集可能使用来自多个Feature View的特征,在生成数据集时,会通过Feature View的Data Source取到这些特征的值
- 特征在线存储同步:特征以Feature View为单位,被同步到在线存储中
- 特征在线消费:特征以Feature View为主体,在消费时被定位和查询
关键组件
元数据存储:AWS S3 / GCP GCS 等对象存储,或本地文件系统,作为Feature Store Registry的元数据存储(Feature Store Registry本质是一系列yaml和python脚本)
离线存储:GCP BigQuery / Google Cloud Datastore,或AWS Redshift / DynamoDB等云数据仓库,用于存储Data Source(其中包含了特征的所有版本),同时也作为特征平台的计算引擎使用,服务于训练数据生成/在线存储同步场景

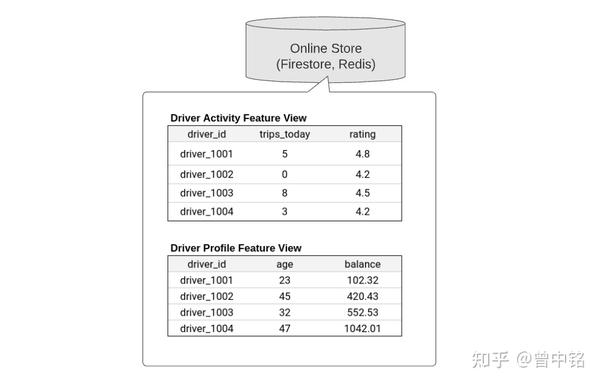
在线存储:Redis等高速存储,用于存储特征的最新版本(即Data Source中各特征的最新时间戳对应的特征值),服务于模型推理时的特征在线消费场景

计算引擎:由离线存储组件承担
使用流程
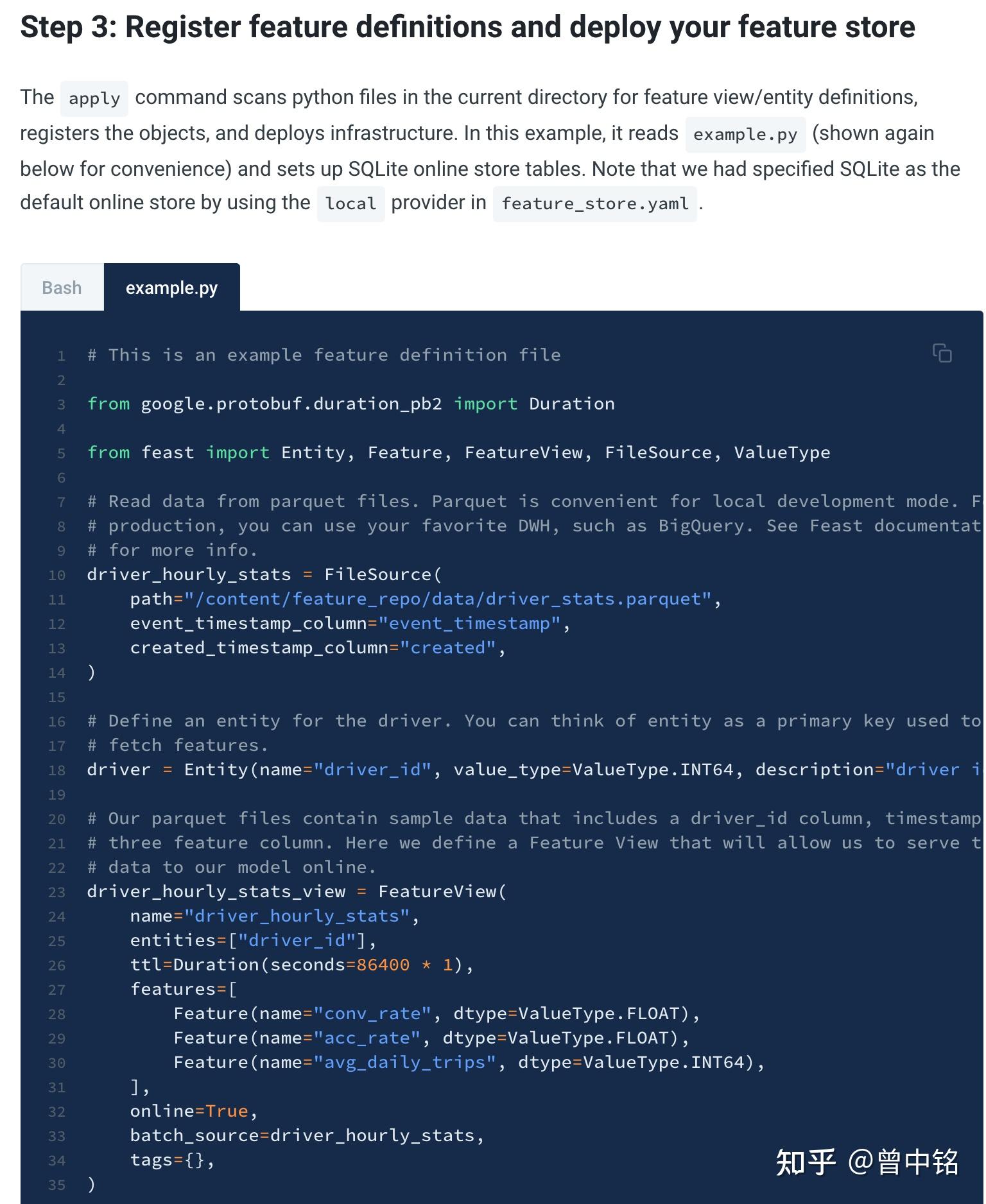
部署阶段


- 生成特征:通过SQL、Spark、Pandas等各种方式生成特征时序表备用
- 创建Feature Repository:实际是编写一系列Python脚本,在其中调用SDK定义Data Source(关联步骤1中的时序表)、Feature、Feature View等对象
- 部署Feature Repository:实例化步骤2中的各对象
使用阶段
- 特征更新:通过SQL、Spark、Pandas等各种方式,持续增量更新特征时序表(即持续更新Data Source)
- 生成训练数据集:通过Dataframe对象提供训练样本列表,调用SDK的get_historical_features方法,从各Feature View中取得特征,并进行Point-in-time Correct Join,供模型训练使用
- 同步特征至在线存储:通过CLI,将各特征的最新版本同步到在线存储
- 在线消费特征:调用SDK的get_online_features方法,通过Feature View配合特征名批量取回特征,供在线推理使用
架构设计分析
Feast对自身的定位是:特征管理服务、特征消费服务的提供者。
同时,Feast还强调了,自身并不承担:
- ETL:Feast不承载数据仓库的ETL计算
- 数据仓库:Feast不承载数据存储,相反,Feast是数据仓库的消费者,在数据仓库之上封装了基于业务(Feature、Feature View)概念的消费能力
- 元数据管理:Feast不负责通用的元数据管理(例如数据血缘、数据Schema等),只聚焦于业务(Feature、Feature View)层级的元数据管理
在这种定位下,Feast与原有的数据仓库、AI算法模型等领域间划清了明确的边界:
#1 不参与原始特征计算
Feast不参与特征日序表的生成过程,而只负责基于现有的特征日序表提供管理、消费能力。
这使得Feast本身很容易与现有的数据流程集成,无论原有数据架构是通过Backfill Data还是Feature Snapshot形式生成特征时序表,只要其符合Feast对特征数据源的要求,就可以通过Feast来管理。
(关于特征时序表生成方式:Backfill Data、Feature Snapshot,详见AI算法模型中的特征穿越问题:工程篇 - 知乎 (zhihu.com))
#2 专注为算法模型提供特征消费服务
对于训练数据生成、线上/线下推理的特征消费场景做了完整覆盖,前者通过将point-in-time correct join流程固化成代码,确保训练数据可以被正确的生成,简化了算法工程师的工作;而后者通过online store同步能力和特征消费SDK,简化了数据工程师的工作。
#3 简洁至上的模块设计
Feast充分地运用了GCP BigQuery、AWS Redshift等云数据库的能力,将piont-in-time correct join运算完全下推,使得Feast本体运行几乎不需要消耗计算资源。
在特征在线消费阶段,Feast封装具体从online store取数的逻辑,对使用者只暴露业务层级(Feature、Feature View)的概念。这一过程通过特征消费SDK实现,模型中只需调用SDK即可实现特征消费,一方面,避免了特征消费服务的部署、维护的工作量,另一方面,也避免了性能瓶颈点的出现。
潜在问题
#1 训练数据生成性能问题
训练数据生成能力,在AI算法模型中的特征穿越问题:工程篇 - 知乎 (zhihu.com),我们介绍了三种典型的实现方式。
对于使用point-in-time correct join方式生成训练集的方法,当面对庞大的特征版本数量时,会遭遇严重的计算效率和存储成本问题。
例如这样一个特征——用户浏览商品序列,其本身是秒级变化的,对于一个日活用户百万的商城来说,仅对于用户浏览商品序列这一特征,一天内需存储的特征时序记录就可能高达千万条。
刨除存储这张特征时序表的成本不说,将数十万、数百万训练样本,关联该表执行point-in-time correct join的计算效率也是十分棘手的问题。
更何况真实的训练数据集可能包含多个类似的特征,每一个都会对存储和计算提出极大考验。
Feast并没有对此问题提出解决办法,通过源码看到训练数据生成的流程是:
- 通过模板生成point-in-time correct join的SQL
- 将SQL完全下推到offline store中执行(并未落临时表,故结果表会存储于offline store的内存中,且根据BigQuery的API默认设定,SQL执行超过5分钟将会自动放弃)
- 将SQL执行结果从offline store拉取到调用SDK的程序的内存中
其中第2步将对offline store的计算、内存资源提出极大考验,如果数据量较大,5分钟内可能SQL都没跑完;即便SQL能顺利跑完,结果集也不一定能装入数据库内存中。
而第3步将整个数据集直接拉取到APP内存中,并未使用任何流式落盘处理,如果数据量较大,APP将直接OOM。
以上都会是实际使用中的问题,目前有人提出相关issue:BigQuery OOM for large datasets · Issue #1591 · feast-dev/feast (github.com),但暂无答复。
#2 online store中特征的时效性问题
online store同步需要通过CLI触发:
- 提交SQL到offline store,获取最新的特征版本值
- 拉取SQL结果集到执行CLI的机器
- 将结果集更新到online store
这一过程使得整个流程的时效性极大下降,特征总是需要先写入offline store,并批量地被同步到online store。
因此,online store中特征的时效性取决于:
- offline store的更新频率
- 同步作业的调度频率
由于同步作业是全量更新,频繁更新会对offline store、online store都造成IO压力,因此时效性很难降低到分钟/秒级。

#3 Registry通过CLI交互,未提供界面
Registry全程通过CLI进行交互,并未提供UI界面。这无疑增加了使用者的学习成本。


#4 Registry无权限管理和审计能力
Feast的Feature Store Registry依赖文件而非数据库进行元数据管理。
这意味着,任何能接触这些文件的人(即任何Feast的使用者),都可以对其进行无审计的修改。缺失了权限管理和审计能力,使得Feast在生产中使用将会存在安全隐患。
另外,通过文件进行元数据管理,可能会在并发修改场景下,造成配置被意外覆盖等问题。


总结
本章中我们提到:
- Feast对于自身角色的定位是特征管理服务、特征消费服务的提供者,为后发的Feature Store提供了设计和架构上的参考
- Feast提出了Feature View这一业务层级的抽象,围绕其建立起特征共享复用、训练数据生成、在线特征消费等能力
- Feast作为开源的、MVP级别的Feature Store,从通用的业务需求出发,设计了简洁漂亮的架构
- 作为一个MVP产品,要在生产中使用它会有较多潜在问题,包括性能、数据时效性、易用性、权限与审计等方面
下一章中,我们将对Feast的商业版Feature Store - Tecton回顾。
